A strange asymmetry now sits at the centre of software delivery. As of early 2026, around 85% of professional developers regularly use AI coding agents, and an estimated 41% of all new code is AI-generated. Implementation that used to take weeks can be done in hours. Yet the work that bookends it - understanding the problem, choosing an architecture, and verifying that what shipped is correct - remains stubbornly human-paced. The bottleneck has moved: not how fast someone can type, but how well the problem is specified and how rigorously the output is checked.
I have just finished Google's new whitepaper on this shift, and it is the clearest framing I have read. "The New SDLC With Vibe Coding" is a free, roughly 50-page paper by Addy Osmani, Shubham Saboo and Dr. Sokratis Kartakis, released as part of Kaggle's 5-day AI Agents course. You can read the whitepaper in an afternoon, and any engineering or data leader should. What follows is my synthesis of its mental models through the lens I keep returning to: AI is a mirror, not an equaliser. It does not lift a weak team to the level of a strong one; it amplifies whatever culture, discipline, and judgment are already there - a theme I have explored in the context of AI-native data teams.
Disciplines, not tools
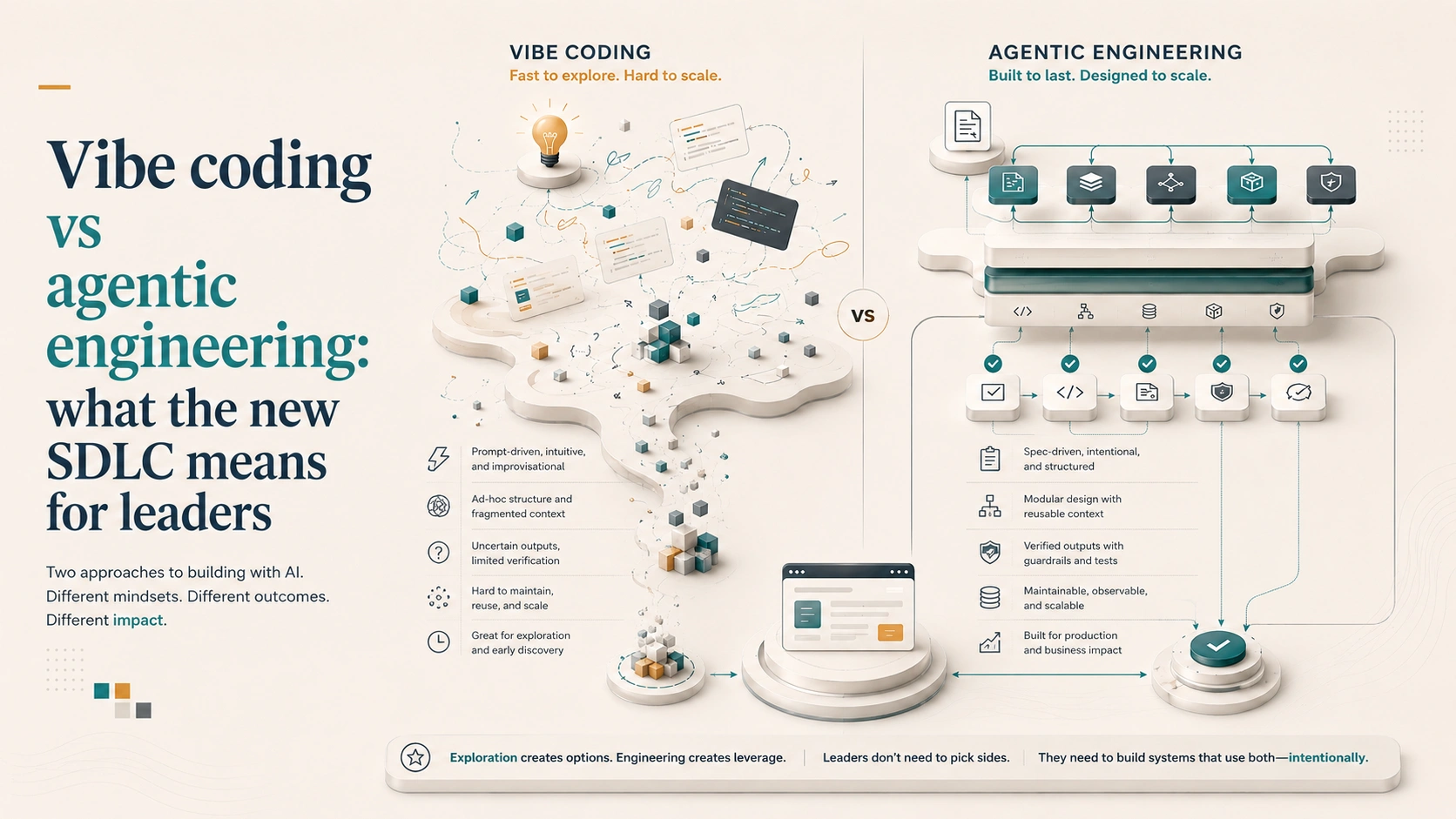
The most useful idea in the paper is also the simplest: vibe coding and agentic engineering are not two tools, they are two ends of a spectrum. The term "vibe coding" comes from Andrej Karpathy in February 2025 - giving in to the vibes, describing what you want, accepting what comes back, and pasting the error message in when something breaks. By early 2026 Karpathy himself had added "agentic engineering" to describe the disciplined end of the same continuum. The differentiator is not whether you use AI - everyone does now - but how much structure, verification, and human judgment surround the output.
At one end sit casual natural-language prompts, a "does it seem to work?" standard of correctness, minimal review, and a high risk profile. That is entirely appropriate for a weekend prototype or a hackathon. At the other end sit formal specifications, automated test suites and evals, CI gates, and architecture review, with a low risk profile suited to production systems and team-scale development. Most real work lands somewhere in between, and the skill is knowing where to draw the line for each task.
The real divider is verification. Tests check the deterministic parts of a system - given this input, the function returns that output. Evals check the parts that are not deterministic - did the agent take the right trajectory, choose the right tools, and produce something that meets the quality bar. Without both, the paper argues, the practice is vibe coding no matter how sophisticated the prompts look. That is a sharp line, and it is why the paper's CTO test is so clarifying: telling a CTO your team is vibe coding the payment system should raise alarm bells. Telling the same CTO your team practises agentic engineering, with AI handling implementation under human-designed constraints and tests ensuring correctness, is an entirely different conversation.
Agent = Model + Harness
The second idea reframes where engineering effort should go. When an agent impresses, the instinct is to credit the model; when it fails, to blame the model. Both instincts are usually wrong. The paper offers a cleaner equation: an agent is the model plus the harness. The model is the engine. The harness is the car, the road, and the traffic laws around it - the rule files (AGENTS.md, CLAUDE.md), the tools and MCP servers, the sandboxes the code runs in, the orchestration logic, the guardrails and hooks, and the observability that tells you whether the thing is working or quietly drifting.
The line I keep quoting is this: "Most agent failures, examined honestly, are configuration failures." Not model failures. A missing tool. A vague rule. An absent guardrail. A context window stuffed with noise. The evidence the authors marshal is hard to argue with. One team moved a coding agent from outside the Top 30 to the Top 5 on Terminal Bench 2.0 by changing only the harness, with no model change at all. A separate study at LangChain raised an agent's score on the same benchmark by 13.7 points by tweaking only the system prompt, tools, and middleware around a fixed model.
For leaders, the takeaway is uncomfortable but valuable: stop over-indexing on model choice. The model you use matters far less than most procurement conversations assume. The harness - the part your team actually owns - is where the leverage lives. Treat it as a shared, versioned asset, not as something each engineer reinvents in a private config file.
Context engineering is the new core skill
If the harness is where leverage lives, context engineering is the discipline that fills it. The paper's central claim is that output quality depends far less on clever prompts than on the quality of context provided. This is the shift from prompt engineering to context engineering, and it is more than a relabelling.
The paper names six types of context every agent needs - instructions, knowledge, memory, examples, tools, and guardrails - and draws a useful line between static context (always loaded: system instructions, rule files, persona) and dynamic context (loaded on demand: skills triggered by the task, tool results, retrieved documents). Static context is expensive because every token is paid for in every interaction; dynamic context is efficient because you pay only when the information is needed. The key pattern for the dynamic side is Agent Skills: packages of procedural knowledge surfaced through progressive disclosure, so an agent can carry dozens of specialisms while paying for only the one in use.
The reframe I find most useful is to stop asking "how do I trick the AI into writing good code?" and start asking "what would a new team member need to know to contribute well, and how do I encode that in a form the AI can use?" That shift turns prompt-whispering into engineering, and it carries a governance implication: AGENTS.md files, system prompts, eval suites, and skill libraries are code. They should be reviewed in pull requests, versioned with the project, and owned by named engineers. Skip that discipline and the harness drifts, behaviour becomes irreproducible across the team. It is the same lesson that applies to data: AI delivers most when it sits on strong, well-governed foundations, not when it is bolted onto a mess.
The SDLC compresses, but unevenly
AI compresses the software development life cycle, but not evenly. Implementation collapses from weeks to hours. Requirements, architecture, and verification do not. The result is not a faster version of the old SDLC - it is a different workflow, where the developer's centre of gravity moves from writing code to designing systems and arbitrating quality.
Architecture stays the most stubbornly human phase. Architectural decisions are about trade-offs - consistency vs availability, build vs buy, complexity vs flexibility - and those depend on business context, organisational constraints, and strategy the model cannot fully grasp. AI is excellent at implementing an architecture once it is decided. It is poor at deciding which architecture the business actually needs.
The mental model that ties this together is the factory model. The developer's primary output is no longer the code; it is the system that produces the code - the specifications, agents, tests, feedback loops, and guardrails. A factory manager does not assemble each widget by hand; they design the line and own quality control. In practice this means giving agents success criteria rather than step-by-step instructions, then letting them iterate against those criteria.
The paper splits the working style into two modes worth naming. The conductor works hands-on and in real time, in the IDE, guiding the AI as code appears - natural for complex logic and unfamiliar code, but a bottleneck if every change runs through one person. The orchestrator works asynchronously, delegating well-specified tasks to multiple agents and reviewing the results; that demands a different skill set - specification, decomposition, evaluation, and system design. And it runs straight into the 80% problem. Agents reliably produce around 80% of a feature; the last 20% - edge cases, error handling, integration points, subtle correctness - still needs human judgment. Worse, the errors have changed character: no longer syntax mistakes a compiler catches, but conceptual ones that look right, read well, and pass basic tests.
The economics leaders actually care about
For engineering leaders, the most important reframe in the paper is economic. The conversation about AI usually begins and ends with velocity. The metric that actually matters is total cost of ownership, and in the AI era operating cost is dictated by the token economy.
Vibe coding looks cheap because its upfront cost is near zero - a subscription and a few prompts. The real cost is hidden and compounding. Developers dump large, unstructured files into the context window and repeatedly ask the model to fix its own unverified output, burning tokens with low first-pass success. Six months later, engineers spend days reverse-engineering AI-generated "spaghetti" - a maintenance tax. And code generated without an evaluation harness produces vulnerabilities just as fast as features, which become costly security remediation in production.
Agentic engineering inverts the curve. It demands real upfront investment - API schemas, deterministic test suites, structured context - so the capital cost is higher. But the marginal cost of shipping and maintaining each new feature drops sharply, because the agent operates inside a governed factory that produces structurally sound, pre-tested output. One lever makes this concrete: intelligent model routing. Rather than paying frontier-model prices for everything, a well-designed system sends the hard work - requirements, architecture, initial implementation - to large models, and routes deterministic work - test generation, review, CI monitoring - to cheaper, faster ones. Comparable quality, materially lower running cost.
How to lead the shift
Pulling the paper's guidance together, here is how I would lead the transition rather than let it happen to me.
Make context engineering first-class. Version the harness, assign owners, and review changes to it like any other code.
Set the bar at the eval, not the demo. A demo proves something worked once; an eval with clear scoring criteria proves it works reliably. Require eval coverage with explicit, well-defined success criteria as a precondition for shipping into any shared workflow, the same way test coverage gates a deploy.
Re-shape code review for AI-generated code. Train reviewers on the new failure modes - hallucinated dependencies and "slopsquatting", thin error handling, and subtle correctness gaps that read perfectly at a glance.
Make the prototype vs production boundary explicit. Decide which projects, branches, and environments warrant vibe coding and which demand agentic engineering. Teams that keep this blurry ship prototypes by accident.
Invest in the harness as shared infrastructure, plan for hybrid teams, and hire for judgment. Reusable prompts, skill libraries, and eval harnesses compound across projects. Humans and agents now work side by side, so handoff protocols, on-call, and team structures must reflect that agents are participants, not just tools - and the most valuable engineers will be the ones who direct agents well, not the ones who type the most code.
Underneath all of it is the thesis I started with: AI is a force multiplier of culture. It multiplies strengths and weaknesses alike, which is why teams with strong testing and architecture cultures extract dramatically more value than those hoping AI will paper over the cracks. How much of this is genuinely new, and how much is another wave to be ridden with judgment, is itself a question I have written about.
Three durable principles
Three principles from the paper will outlast whichever tools are fashionable next year. Structure scales; vibes do not. AI amplifies your engineering culture, for better and worse. And the human role is evolving, not diminishing - shifting from implementation towards specification, evaluation, and architectural judgment. The authors land it in a single line worth pinning above any team adopting these tools: "Generation is solved. Verification, judgment, and direction are the new craft."
In short
Google's new SDLC whitepaper draws a clear line between vibe coding and agentic engineering, and the line is verification, not tooling. For leaders, the practical lessons are concrete: invest in the harness and the context, not just the model; set the bar at the eval rather than the demo; make the prototype vs production boundary explicit; and hire for judgment. Generation is largely solved. Structure scales where vibes do not, AI amplifies whatever culture it lands in, and verification, judgment, and direction are now the craft that separates teams shipping dependable software from teams merely shipping fast.